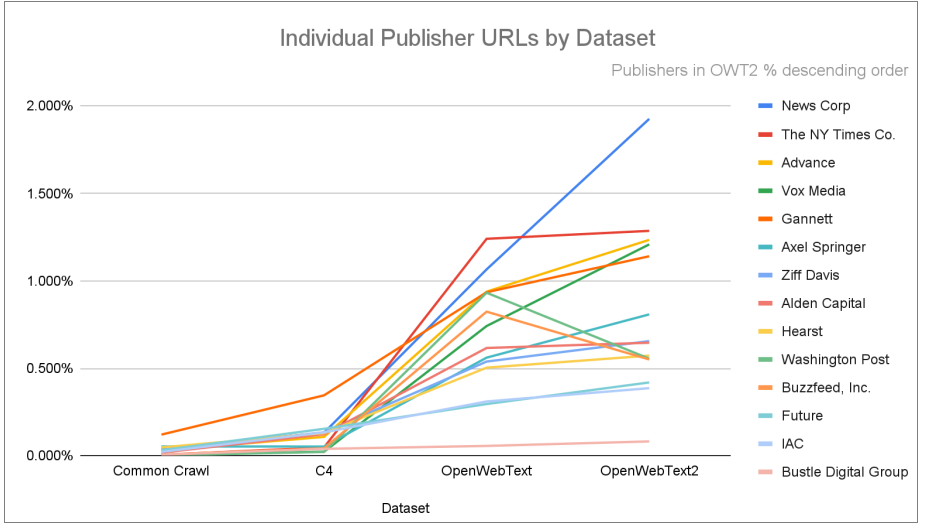





A recent study by Ziff Davis reveals that major AI companies like Google, OpenAI, and Meta are increasingly relying on content from trusted news sources when training their language models. This approach highlights the significance of high-quality media content in shaping the information that chatbots provide. The findings suggest that prominent publishers, such as News Corp and The New York Times, may have stronger grounds for seeking payment or copyright protections for their material, as AI companies benefit from using it without compensation. The ongoing debate around content usage raises concerns about the financial future of media organizations essential for delivering reliable information in the AI-driven landscape.
AI companies like Google, OpenAI, and Meta are increasingly focusing on using content from trusted news sources when developing their large language models (LLMs). A recent study by Ziff Davis revealed that these major players in the AI field prioritize high-quality media content during training. This shift could provide insights into how chatbots, which rely on vast amounts of information, gather their knowledge and can give traditional media companies like News Corp and The New York Times a stronger case for seeking copyright protection or compensation for their material.
The study highlighted that many LLM training datasets rely heavily on content from respected publishers, suggesting that these companies could be missing out on significant licensing revenue. OpenAI, for example, weighs high-quality datasets, like news articles and popular online posts, more heavily in its models, thus shaping the type of responses these systems generate.
Ziff Davis, which owns PCMag, pointed out that without fair compensation for their content, news publishers might struggle to survive in the evolving AI landscape, potentially disrupting the supply of reliable information. This issue has become increasingly pressing as some media organizations have taken legal action against AI firms for using their content without permission, with mixed results in court.
This ongoing discussion emphasizes the delicate balance between advancing technology and supporting the creators of the high-quality information that fuels it.
Tags: AI, Language Models, Copyright, News Media, OpenAI, Google, Meta, Ziff Davis, Content Creation, Technology News.
- What does it mean that Google and OpenAI use news content for AI training?
It means they use articles and reports from news sources to help teach their AI systems how to understand and generate human language.
- Why do they do this without paying for the news content?
They may argue that using public news content helps improve their AI and provides benefits to both the AI tools and the public, but this can raise questions about fairness for the news creators.
- How does this affect news organizations and journalists?
News organizations may feel it’s unfair because they create original content but don’t get paid when it’s used to train AI. This can impact their revenue and business models.
- Are there any legal issues with using news content in this way?
Yes, there are ongoing discussions about copyright laws and whether it’s fair use to take news content for AI training without compensation. It’s a complex legal area.
- What can content creators do about this situation?
Content creators can advocate for fair compensation by raising awareness and pushing for new laws or agreements that ensure they are paid when their work is used to train AI models.
